1 | 1. 备份一般都会在备库上执行,在用–single-transaction 方法做逻辑备份的过程中 |
冒险和预测(21~26讲)
CPU流水线设计
指令流水线: 若把指令执行拆分成取指令 -> 指令译码 -> 指令执行 三个部分、这就是一个三级的流水线、若把指令执行进一步拆分成 ALU
计算(指令执行) -> 内存访问 -> 数据写回 就变成了5级流水线、
1 | 五级流水线: |
超长流水线性能瓶颈
1 | 增加流水线的深度是有性能成本的 |
流水线设计的冒险
流水线设计需要解决的三大冒险: 结构冒险, 数据冒险 和 控制冒险结构冒险: 本质上是硬件层面的资源竞争问题、CPU在同一个时钟周期、同时在运行两条计算机指令的不同阶段、但可能会用到同样的硬件了

1 | 如上所示: 在第一条指令执行到访存(MEM)阶段的时候、流水线里的第4条指令、在执行指令Fetch的操作、访存和取指令、都要进行内存数据的读取, 内存只有一个地址译码器的作为地址输入、就只能在一个时钟周期里读取一条数据、无法同时执行第一条指令的读取内存数据和第4条指令的读取指令的操作 |
在CPU的结构冒险里、对于内存访问和取指令的冲突、直观的解决方案是把内存拆成2部分、让他们有各自的地址译码器、分别是存放指令的程序内存和存放数据的数据内存(对应体系结构叫 哈佛架构(Harvard Architecture)), 但这样拆对于指令和数据需要的内存空间、就无法根据实际的应用动态分配了、解决了资源冲突问题、也失去了灵活性
现代CPU架构借鉴了哈佛架构的思路、采用了普林斯顿架构、在高速缓存方面拆分成指令缓存和数据缓存
内存的访问速度远比CPU慢、所以现代的CPU不会直接读取主内存、会从主内存把指令和数据加载到高速缓存中、这样后续访问都是访问高速缓存、而指令缓存和数据缓存的拆分使得CPU在进行数据访问和取指令的时候、不会发生资源冲突了
数据冒险: 三种不同的依赖关系
1 | 数据冒险就是多个指令间有数据依赖的情况、可以分为 先读后写、先写后读和写后再写、如果满足不了依赖关系、最终结果就会出错 |
通过流水线停顿(Pipeline Stall):插入nop操作 来解决数据冒险
操作数前推
1 | add $t0, $s2,$s1 |

乱序执行
1 | 即使综合运用流水线停顿、操作数前推、增加资源等解决结构冒险和数据冒险的问题、仍然会遇到不得不停下整个流水线等待前一指令完成的情况、但是: 如果后边有指令不需要依赖前边指令的执行结果就可以不必等待前边指令完成、直接占用nop即可、这样的解决方案、在计算机里叫 乱序执行 |



乱序执行的步骤
1 | 1. 取指令和指令译码阶段、同其它CPU、会一级一级顺序进行Fetch和Decode |
分支预测
缩短分支延迟: 将调解判断、地址调整 提前到指令译码阶段进行、无需放到指令执行阶段. 这种方式本质上和数据冒险的操作数前推方案类似、就是在硬件电路层面讲一些计算结果更早的反馈到流水线中、反馈更快、后边指令的等待时间就变短了
分支预测: 1) 静态预测、假装分支不发生. 分支预测失败的代价是: 丢弃已取出的指令&清空已使用的寄存器的操作
2) 动态分支预测:
a. 一级分支预测: 用1比特、记录当前分支的比较清空、来预测下一次分支时候的比较情况
b. 双模态预测器: 从2byte记录对应状态、提高预测的准确度
1 | 的流水线设计里、会遇到eg. 指令依赖等的情况、使得下一条指令不能正确执行. 但是通过抢跑的方式、可以得到提升指令 吞吐率 的机会、流水线架构的、是主动的冒险选择 |
流水线设计总结
1 | 为了不浪费的性能、把指令执行的过程切分成一个个的流水线、来提升的吞吐率, 而每增加一级的流水线、也会增加overhead、同样因为指令不是顺序执行 |
建立数据通路(17-19讲)
指令周期
1 | 计算机每执行一条指令的过程、可以分解为: |
Machine Cycle: 又称为机器周期或者CPU周期, CPU的内部操作速度很快、但是访问内存的速度却慢很多、每一条指令都从内存中加载而来、所以一般把从内存中读取一条指令的最短时间称为CPU周期
Clock Cycle: 也就是时钟周期及机器的主频、一个CPU周期通常是几个时钟周期的积累、一个CPU周期的时间、就是这几个时钟周期的总和
对于一个指令周期来说、取出一条指令、然后执行、至少需要两个CPU周期、取出指令至少需要一个CPU周期、执行也至少需要一个CPU周期、复杂的指令需要更多的CPU周期
so. 一个指令周期包含多个CPU周期、而一个CPU周期又包含多个时钟周期
建立数据通路
1 | 一般来说、数据通路就是处理器单元、通常有两类元件组成 |
控制器: 可以看成只是机械的重复 Fetch -> Decode -> Execute 循环中的前两个步骤、然后将最后一个步骤通过控制器产生的信号、交给ALU去处理
1 | 控制器电路听起来很简单、其实特别复杂, |
CPU所需要的硬件电路
1 | 要想搭建CPU、需要再数字电路层面、实现一些功能. |
时序逻辑电路
1 | 解决了以下问题: |
时钟信号的硬件实现
1 | 时钟: CPU的祝您是又一个晶体振荡器实现的、而这个晶体振荡器生成的电路信号、就是时钟信号 |
通过D触发器实现存储功能
1 | 将R和S两个信号通过一个反相器合并、可以通过一个数据信号D进行Q的写入操作 |
PC寄存器所需要的计数器
1 | PC寄存器还有个名字叫程序计数器、为什么呢 ? |
读写数据所需要的译码器
1 | 现在数据可以存储在D触发器里了、若将多个D触发器放在一起、就可以形成很大的一块存储空间、甚至可以当成一块内存来使用、 |
因为从内存取指令的时间很长、若使用单指令周期处理器、意味着我们的指令都要去等待一些慢速操作、这些不同指令执行速度的差异、也正是计算机指令有指令周期、CPU周期和时钟周期之分的原因、因此, 优化现代CPU性能时、用的CPU都不是单指令周期处理器、而是通过流水线、分支预测等技术、来实现在一个周期里同时执行多个指令
再忆陈情
年关、慵懒极了、想看看电视剧、读读小说、结束一年的忙忙碌碌.
看了庆余年、看评论提到了 陈情令、初播便得到很多好评的一部电视剧, 彼时未得闲暇、未曾顾及, 此时看到、不免心生欢喜.
回忆开头、未懂, 不明所以, 剧情渐入回忆, 我渐渐沉迷...
想以人物为主线、理理自己的思绪、乱七八糟、若不慎入眼、看看且过即可...
绵绵: 善良正直真性情的小女孩、也算是剧中最幸福的一个, 地位不高、
首次出现在与金子轩一起去云深不知处听学时、那时结识魏无羡.
后在被温氏要挟、去不夜天听训时、被魏婴救过(挡下烙铁).
射日之征后, 魏婴被诬陷、绵绵挺身而出、直言 魏婴不是这样的人, 遂脱离金家氏族.
最后一场戏是魏婴、蓝忘机再次去乱葬岗时路过山野小屋、竟是绵绵与丈夫、还有一个乖巧的女儿、
也叫绵绵, 只怕是绵绵无尽的思念也未可知~
结局也算美好、在告别金家氏族、告别蓝忘机之后、远离了`正义`, 活成了自己喜欢的样子.
戏份不多、确是活的最洒脱的女子.
薛洋: 作恶多端、却无法相恨, 他坏、但坏的明明白白, 恨不起来大概是因为他受过的那许多的苦.
从小遭受了太多世界的冰冷、从未感受过暖、世界不曾教过他、又缘何怪他不懂 ?晓星尘给他点滴的爱、
他就把晓星尘放在心头, 若他成长的道路上有阳光、他何尝不会是一个好孩子 ?
或许有很多朋友愿意说、魏婴也遭受了很多打击与诬陷, 区别就在于所有的遭遇处于人生哪个阶段罢了.
三观构建完成、就有了判断力、忍耐力、有了思考. 偏偏薛洋在人生最关键的时候遭受的都是冰冷,
从未有一米阳光, 对这个很坏的孩子更多的是同情吧、愿下一世、有阳光普照、有温暖与美好、
带着你的聪慧、做个阳光明媚的孩子、一如你喜欢的晓星尘...
晓星尘、宋岚: 明月清风晓星尘,傲雪凌霜宋子琛, 开场被他们深深吸引、可惜戏份不多, 再出现已难回首...
愿悲情的你们、下一世真正的活成明月清风. 也愿彼此间多一些信任, 就如 蓝湛和魏婴 ~
魏婴: 魏无羡 (夷陵老祖)、年少时经过几年流离生活、后被江枫眠带回江家、收为弟子、初始、
江澄不喜欢他、但孩童总是天真、很快就成为好友、又有阿姐的悉心照料, 生活也算幸福、自身天赋极高、
很快成为同辈里的佼佼者、排名仅在姑苏双壁之下, 修为极高、性格跳脱、善良随性、师姐的话就是
`阿羡大事从不胡闹`, 佩剑取名`随意`、可见一般、活脱脱已调皮任性的小公子、但为人极善良、
很多细节、他应该是将师姐看作母亲一般、在她面前任性、一副小孩子的模样、惹得江澄嫉妒,
后在云深不知处结识蓝二公子、调侃他`披麻戴孝`、偏生又爱挑逗他、此后接下不解之缘, 后在玄武洞
救下绵绵、还惹得蓝二公子一身醋意, 身受重伤的他、挑逗忘玑、他要听歌、忘玑创作 `忘羡`,
随后温氏不满、欲灭江氏一族、为救江澄、舍弃自身金丹, 后被丢入乱葬岗、创造阴虎符.
射日后、力保温情族人、与众人为敌; 后与温氏族人一起在乱葬岗生活了一段时间, 也就是在此时、
温宁开始对他不离不弃. 后金子轩惨死、温宁温情姐弟不忍拖累他、然后去自首、被挫骨扬灰(后证实宁未死)、
接近崩溃的魏婴孤身来到不夜天与众人对峙, 师姐又为挡剑而死、当场崩溃、心如死灰
十六年后、魏婴重生、亦是蓝湛的重生, 那个问灵十三载的少年郎...
后师姐问及笛子叫何名字、遂取`陈情`, 且不乱猜、各人心想吧; 从`随意`到`陈情`, 承载了多少苦难?
还好本心善良的魏婴和蓝湛一起重生、蓝湛将内心疮痍的`夷陵老祖`又养成了一个`小可爱`,
会撒娇、会调侃、会躲在身后~~~. 他知道蓝湛哥哥一定会护他周全...
愿来生、还是那个偏偏白衣少年郎~~~
江澄: 江晚吟, 背负太多家族使命, 性格里有很多怯懦、也有许多坚强、从小被魏婴的光环笼罩、
内心好强、想要胜过魏婴、却处处比不过、但也是从心底里心疼魏婴, 在乱葬岗为了家族、
一剑刺在乱石上、这一剑、又何尝不是救了魏婴 ? 若不是他、必是别人、那时候怕刺的不再是石头...
莲花坞被侵占时、身心俱碎、发现外出为姐姐买药的魏婴将要被温氏发现时、挺身而出、
让自己成为目标, 后被化丹手化去金丹, 一心好强的他、痛不欲生 ...
这些何尝不是坚强?何尝不是关爱?有时对魏婴的挑剔怕是来源于亲昵的任性、心底的依赖...
在穷奇道、魏婴就走温清族人、在乱葬岗下、魏婴带着温情族人一起生活、他气愤, 又怎么不是
来自于想要被魏婴保护的渴望 ? 姐姐虽对他们万般宠爱、终究帮不了太多、一个十几岁的孩子
突然成为偌大的江氏家主、心中不免惶恐, 重建莲花坞、保护家族的重任就落在了他的肩上、
注定不能成为魏婴一般潇潇洒洒的人....
十六年后、与魏婴重聚、他生气、为何不先来找他、也是源自心底那份情吧? 有些话说得不合适、
但难掩心中的善、不是如同魏婴那般孤注一掷的善、彻彻底底的善、因为背负了太多的使命吧.....
愿你来生、只做个任性的小公子、哎、你又这么好强、该如何是好?
江厌离: 暖情小姐姐、若得此姐、此生足矣. 在虞紫鸢强势的性格下居然能长出如此温婉的性格、着实不易、
从小就保护阿羡、阿澄, 给他们煲汤、调节他们的不愉快. 无论是师姐的身份还是姐姐的身份,
他都是合格的、江澄和魏婴对她也都是依赖的, 在去往云深不知处时、偶遇未来夫婿金子轩,
开始喜欢他, 但此时子轩并不喜欢厌离、一番波折、总算是相互欢喜, 不料、在孩子满月酒宴时,
由于金光瑶捣乱、苏涉乱吹笛、导致温宁失控、误杀金子轩. 暖心的姐姐并没有恨魏婴、她相信他
是发自心底的信任, 一刻也不曾动摇. 在她心里、羡羡和阿澄是最好的弟弟. 有次夜猎、
魏婴被金家人侮辱`家仆之子`, 厌离挺身而出、一改柔弱、说`他是我弟弟、不是外人`, 要求对方道歉.
愿来生, 所爱之人携手白头、疼爱的弟弟膝下承欢, 愿小小心愿都能称心如意...
蓝湛: 蓝忘机, 含光君, 也是剧中称呼最多的一个(都是羡羡给的~~~), 有很多坎坷、也有很多甜美、
雅正端方、严于律己、逢乱必出...
遇到魏婴之前、清冷如冰, 遇见之后慢慢的因为知己、后深不可离...
从最初的高傲冰冷变得调皮、玄武洞内调侃魏婴的情节、大概暖到了很多人. 魏婴帮他包扎伤口、
上凝血草时、他突然抓住魏婴的手、将凝血草敷在了救绵绵时留下的烫伤上、顺便来了一句: 不用谢、哈哈~
羡羡救绵绵、恐怕含光君还吃了一潭子醋、正经答道 `你要是没那个意思、不要随便撩拨别人`
没忍住笑喷了, 含光君居然会这么可爱~, 一本正经的可爱这么好玩儿~~~
他们也经历了很多的磨难、玄武洞、不夜城、穷奇道、乱葬岗...
心一点点的被揪着, 不敢放松.
魏婴出事后、第一次违反家规、被罚3年禁闭、出来之后、无时不在寻找. 问灵十三载、等一不归人
大部分剧友都觉得刻骨难忘吧 ?待到被问时、只轻轻一句、我有悔, 不夜天没有和你站在一起.
十六年里、受过魏无羡受的伤, 喝过魏无羡喝过的酒, 种魏无羡种过的思追, 气魏无羡气过的蓝启仁,
违反过魏无羡违反的家规, 将阿苑带回云深不知处、取字思追(思君不可追), 将思追养成了魏无羡、
一样善良肆意洒脱、敢于做自己, 一样的善良热血、将破魔咒珍藏了16年.
十六年后、魏婴复生、成为魏婴最真切的守护神、凭借`忘羡` 立即认出魏婴、此后对魏婴可谓无微不至的
关怀、不允许别人对他丝毫的伤害、魏婴怕狗、躲在忘玑身后的情节也是温暖了很多剧友~~~,
醉酒抓鸡的情节也是深入人心. 魏婴被欺负时、他对哥哥说、我想带一人回云深不知处、藏起来...,
被人戏称`护妻狂魔`,^.^~
愿来生, 温润如玉、有母爱陪伴、多些笑容、早遇知己, 愿给你所有的美好
蓝涣: 蓝曦臣, 泽芜君. 与弟弟含光君一起并称`姑苏双壁`, 清煦温雅、永远都是那么善良、那么温柔、理智
修为极高、从不欺负弱小、若他称谦谦公子第二、怕是没人敢居第一吧?整部剧除了两个情节失态、
一直是温润如玉、长者之风、十分疼爱弟弟忘玑、初见魏婴、觉得适合做弟弟的朋友、便各种暗示
可以猜透忘玑心中所想, 魏婴身死魂消后、一直陪伴在侧. 道出忘玑身上戒鞭痕来历、
又在云梦观音庙吐露忘玑对魏婴的13年苦守、促使二人心意相通
一直拿金光瑶当成最好的朋友、聂明玦和金光瑶关系不和、他居中调节、魏婴回归后、发现金光瑶
所做的事情、他不愿相信、对忘玑说: 你相信魏婴、我相信阿瑶、他是你的知己、阿瑶也是我的知己(非原话).
又将随意出入云深不知处的令牌给金光瑶, 可见信任非同一般. 可惜、金光瑶却真实的死在了他手上、
恐怕心中的痛无人能晓吧 ?愿有人将你温暖、替你扛下一些使命...
之前温氏毁掉云深不知处、打伤他最疼爱的弟弟、害他狼狈出逃、在清缴温氏时、
他依然冷静的将温情与温家分开、仗义执言、不迁怒于人、难能可贵.
借言百度百科:
1. 蓝曦臣沉吟道:"这位温情的大名我知晓几分,似乎没听说她参与过射日之征中任何一场凶案的。"
聂明玦道:"可她也没有阻拦过. "
蓝曦臣道:"温情是温若寒的亲信之一,如何能阻拦?"
2. 聂明玦道:"英魂长存" 蓝曦臣道:"愿安息. "
他的心底相信魏婴做的不算冤枉吧?只是敌人、仇人死了、他依然愿意安静的道一声"愿安息".
来生、愿你仍为翩翩君子、温润如玉、愿你有属于自己的幸福、有人疼、有人爱、不用一人担尽天下心.
蓝思追: 阿苑, 从小漂泊、经历不夜城被毁、同族人一起经历不幸、后被魏婴救出、带领他们生活在乱葬岗下.
还好、余生皆是暖情. 小小年纪、还不知凄苦悲凉、有族人陪伴、魏婴逗玩、在乱葬岗依然生活的快乐、
被魏婴当成萝卜种在地里的情节好暖心, 后被蓝二哥哥效仿羡羡当成小兔子种、哈哈哈、好温暖~~~
小时候称蓝二哥哥有钱哥哥、喜欢抱大腿儿(~.~), 魏婴出事后、被蓝二哥哥悄悄收养、改名 蓝苑、字思追.
在蓝湛的培养下、变成一个谦谦君子、又糅合了魏婴的灵动、善良、恣意洒脱、挺招人喜欢的, 初见鬼将军很怕、
但不让人伤害他, 初见十六年后的魏婴、不让别人欺负他、善良的孩子~~~
愿来生、满满的岁月静好 ....
温晁: 温若寒小公子, 嚣张跋扈、高傲自大、行径恶劣. 喜欢显摆、因为不满江家不服从温家的指令,
所以找了个借口把江家灭门。魏无羡和江澄虽然有幸逃过一命,但是江澄的金丹被温逐流炼化,
彻底丢失了灵力。而魏无羡在把金丹给了江澄后,被温晁丢进乱葬岗里
剧中、我真心找不到他的一点儿善良...
就算在最后、都还在斥责温逐流、彻彻底底很可恶的一个人, 愿来生、学会善良、读懂温暖...
温情: 岐山温氏人、一个旁支、高傲能干的妙手神医, 内心善良. 倾尽全力的保护族人、保护弟弟,
不夜天听训时、被温若寒恐吓、为了弟弟安危、告诉弟弟不要乱跑、不要和魏婴混在一起, 自己却逮着机会就帮助魏婴,
后莲花坞被温氏侵占、江枫眠和虞紫鸢被害、收留江家姐弟并为他们疗伤, 又帮助魏婴实现换丹.
最悲情的角色、天性善良、不作恶、却是剧中唯一被挫骨扬灰的一个...
来生、愿安好、与自己的族人过着静美的小日子 ~~~
温宁: 暖心的小天使、从小被抽去一部分灵识、显得呆呆傻傻, 因魏婴在云深不知处赏识、
内心孤僻的温宁从此感恩、在不夜城救过魏婴、在莲花坞被毁时帮过魏婴, 射日后、魏婴在穷奇道救下
温宁及其族人、后成为`鬼将军`(傀儡)但保留了意识、功力大增、听魏婴吹笛杀人、后被金光瑶控制
十六年后重逢与魏婴重逢、拔出他头部的铁钉、更加只听魏婴一个人的、称他为`公子`.
整部剧一直感觉他是一个温暖的小天使, 呆萌可爱 ...
愿来生, 他可以生的美好、做一个暖情的小公子, 弥补此生的孤独.
愿来生只做白衣少年温琼林...
金子轩: 金家公子、为人高傲、但心底善良、敢于追求内心的爱、人物着墨不多. 来生, 愿幸福~~~
金光瑶: 人物性格比较复杂、表面温和、内心阴暗、但真心帮助蓝曦臣. 剧里做了很多坏事、最终也只是
为他人做嫁衣、母亲虽为艺伎、不多的着笔、却让人难忘、是一个温和、知书识礼的好母亲
后来利用蓝曦臣(清心音)设计杀害聂明玦、并做成凶尸. 为了得到秦仓业支持、娶同父异母
妹妹秦愫、又为免受非议、杀死亲生子金如松. 为了夺取金家地位、杀死父亲金光善. 与薛洋一般、
是一个缺少温暖的孩子、内心有太多的恨与恶、千般不该、设计杀死聂明玦、那个曾经给他支持、
拿他当亲兄弟对待的人. 就算知道他放走薛洋、也只是把他赶出去、并未伤害他、这样的人都伤害、
心中有个无法原谅的坎儿....
来生、愿其母觅得良人、给他一个温暖的家, 愿多些温暖、少些心中阴霾.
聂怀桑: 初时、同魏婴一般、算是志趣相投. 修为不高、成为家主之后被称为: 三不知、然而看似柔弱无害
的他, 确是藏的最深的一个、剧中有很多伏笔, 比如: 十六年后说书人说到夷陵老祖时的回头一看
大梵山假的舞天女重生
温家墓前的扫墓老丈其实是聂怀桑...
从魏婴十六年后重生到后续的情节、由他一人策划、只为复兄仇, 算不
得坏、不是大奸大恶之人、亦无泽芜君的容人之量、终究是被内心的情感左右、算不得对、算不得错、
好在、此后任逍遥~~~, 也没什么野心、亦真心喜欢和魏婴做朋友.
来生、愿有哥哥一生庇佑、只做恣意山水的快活少年.好多情节、令人禁不住落泪、或是真情流露、或是温暖荡漾、或者是悲情感慨, 人物是复杂的、性格是综合的、确也更符合现实的人性吧. 世上人心终是横看成火、侧看成冰. 本着不讨论的原则写文、可能还是注入了不少自己的感情、魏婴和蓝湛的爱情也实在太感人了耶、^*^ 、闲来无事可以看看~
附图册:








mq选择
基本标准
- 开源: 遇到有问题的bug可以通过修改源码的方式来修复或者规避、而不是只能等待下一个官方版本发版来修复
- 产品社区有一定活跃度: 遇到问题的时候、可以快速找到类似场景、快速修复, 相比于每一个bug都需要自己通过阅读源码来解决、毕竟线上问题挂着的的成本很高
社区活跃度较高的产品、与周边应用的兼容性也会比较好、省去很多造轮子的时间 - 性能要求:
1) 确保消息可靠传递、不丢失消息
2) 支持集群、确保某个节点宕掉不会影响整个服务
3) 性能、能满足大部分实际需求场景的需要
目前可选方案
RabbitMQ
1 | 源码实现 : Erlang |
RocketMQ
1 | 2012年阿里开源出来的产品、17年交给apache维护 |
Kafka
1 | 最初设计是为了处理海量日志、早期版本不保证消息可靠性、也不支持集群、但对于处理海量日志这个诉求是比较好的选择 |
第二梯队mq
ZeroMQ
严格来说不能算是消息队列、而是一个基于消息队列的多线程网络库
如果需求是将消息队列的功能集成到系统进程中、可以考虑ZeroMQ
ActiveMQ
社区已经不活跃、进入了老年期
使用 hexo 框架搭建网站
使用 hexo 框架搭建网站
先搭建基础环境
1 | brew install node // 安装node |
安装hexo
1 | npm install hexo-cli-g // 安装hexo |
此时、本地网站已经搭建完成, 访问 localhost:4000 即可.
配置文件 _config.yml
1 | title: 牛牛的Blog |
更换主题
1 | 下载: https://hexo.io/themes/ |
分类和标签
1 | hexo new file-name (file-name是你的文章名, 也可以直接在 spurce/_post 文件夹下新建md文件) |
打开 source/tags/index.md、修改为:
1
2type: "tags"
comments: flase
1 | hexo new page categories // 打开分类功能 |
打开 source/categories/index.md、修改为:
1
2type: categories
comments: false
使用:
1
2
3
4
5
6
7
8 在文章头部添加
tags:
- tag1
- tag2
- tag3
categories:
- cat1
- cat2
修改hexo侧边栏标签
1 | menu: |
注意: :前边展示的是侧边栏显示名称
/xxx/ 展示的是分类名称
|| 后边是图标
图标从 fontawesome.com 获取
将链接修改为蓝色
打开themes/next/source/css/_common/components/post/post.styl 文件, 将下面的代码复制到文件最后
1 | .post-body p a{ |
修改代码块样式
打开 themes/next/_config.yml, 搜索 custom_file_path, 去掉 style 前边的注释, 然后新建或者打开 {blog_root}/source/_date/styles.styl 文件
1 | code { |
使用valine评论系统
新版本的 https://valine.js.org/ 支持npm安装
1 | # Install leancloud's js-sdk |
新的版本next主题已经默认支持, 需要注册leanCloud账号 https://leancloud.cn/, 获取appId和appKey, 然后修改配置文件 **themes/hexo-theme-next/_config.yml**, 搜索 valine, 修改配置项:
1 | # Valine. |
将 enable 改为 true, 将刚刚申请的 appId 和 appKey 填入,
leancloud appId申请请参考: https://valine.js.org/quickstart.html
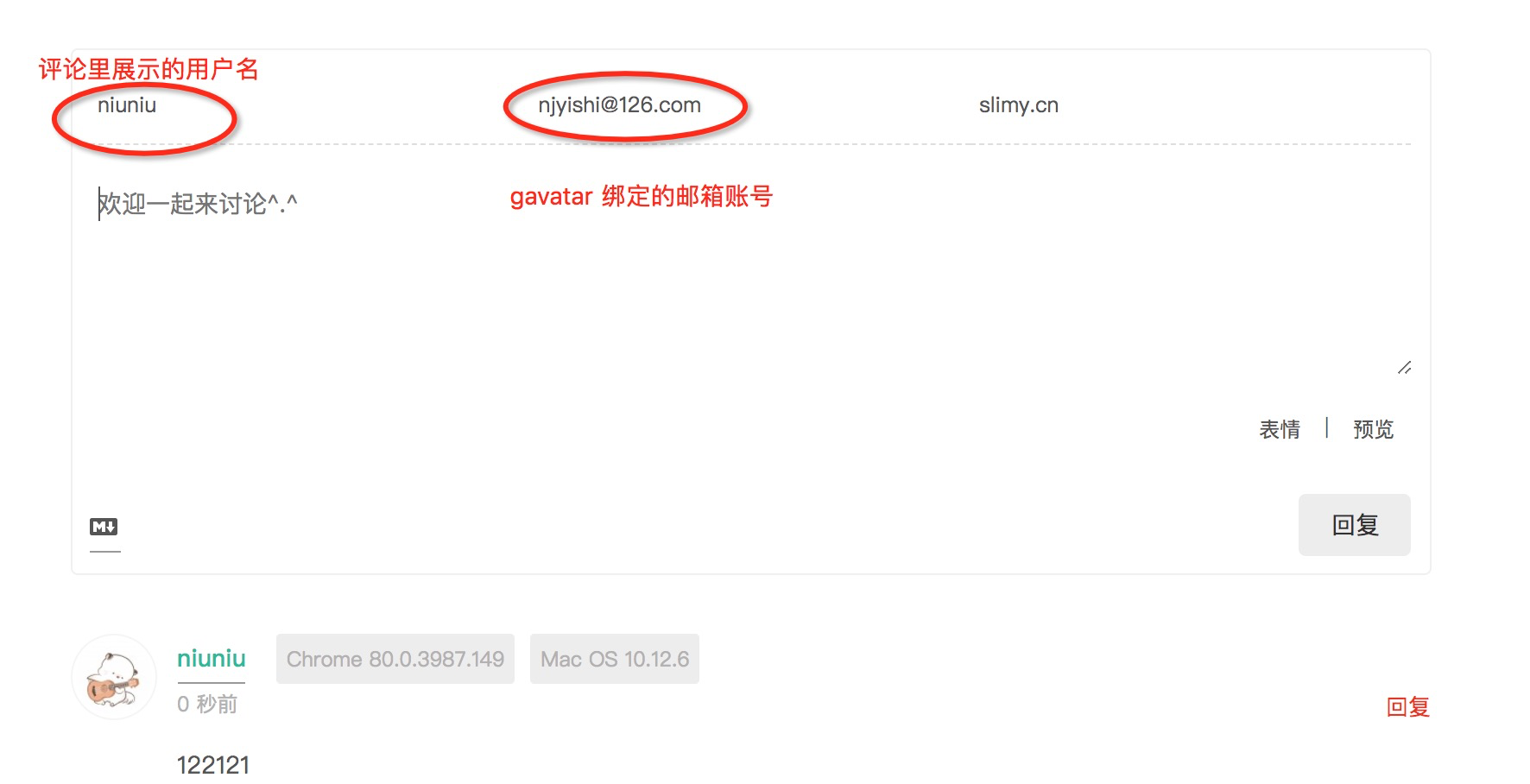
评论头像显示
注册 gravatar, valine 默认使用 gravatar的头像管理
进行评论, 注意要在评论时填写自己注册后绑定的邮箱、才会显示头像
如下图所示
如何同时登陆两个github账号
生成一个新的ssh key
1 | nj:~ nj$ cd ~/.ssh |
- 打开新生村的
~/.ssh/id_rsa_personal.pub文件、将内容添加到 github 后台 - 打开
~/.ssh/config文件1
2
3
4Host xxx //你的host别名
HostName github.com
User yyy //github的注册用户名
IdentityFile ~/.ssh/id_rsa_personal - 将github ssh仓库中的 git@github.com 替换成新建的Host别名
1
2eg. git@github.com:hbxn740150254/BestoneGitHub.git
-> git@xxx:hbxn740150254/BestoneGitHub.git